DATASETS, BENCHMARKS, AND PROTOCOLS
Assessment of Large Language Models in Clinical Reasoning: A Novel Benchmarking Study
Liam G. McCoy, Rajiv Swamy, Nidhish Sagar, et al
NEJM AI 2025;2(10) Published September 25, 2025
DOI: 10.1056/AIdbp2500120
Abstract
BACKGROUND
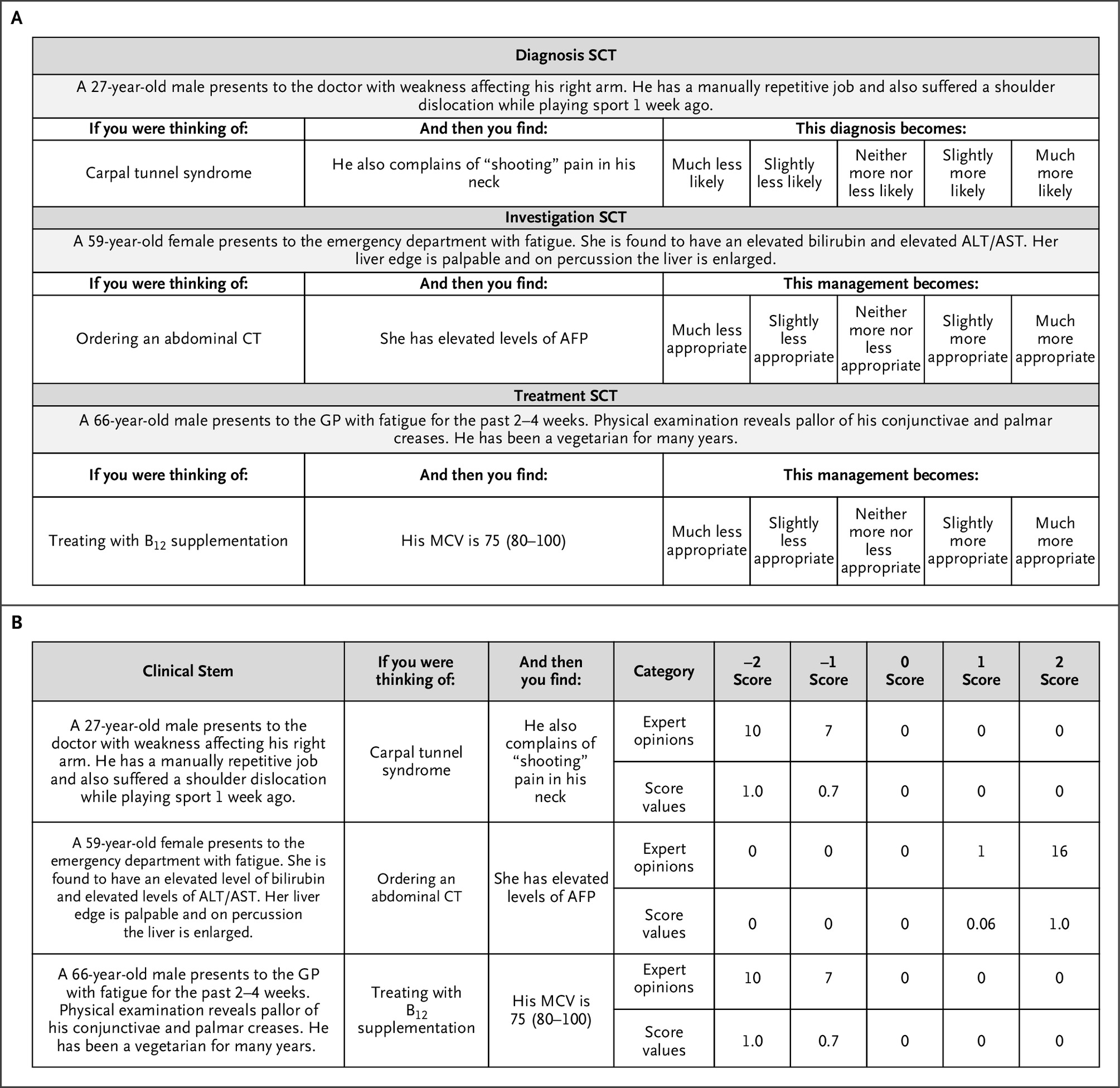
Large language models (LLMs) are increasingly deployed for clinical decision support, yet standard evaluations such as medical licensing exams overlook how clinicians update decisions in dynamic contexts. Script concordance testing (SCT), a decades-old assessment tool, measures how new information adjusts diagnostic or therapeutic judgments under uncertainty.
METHODS
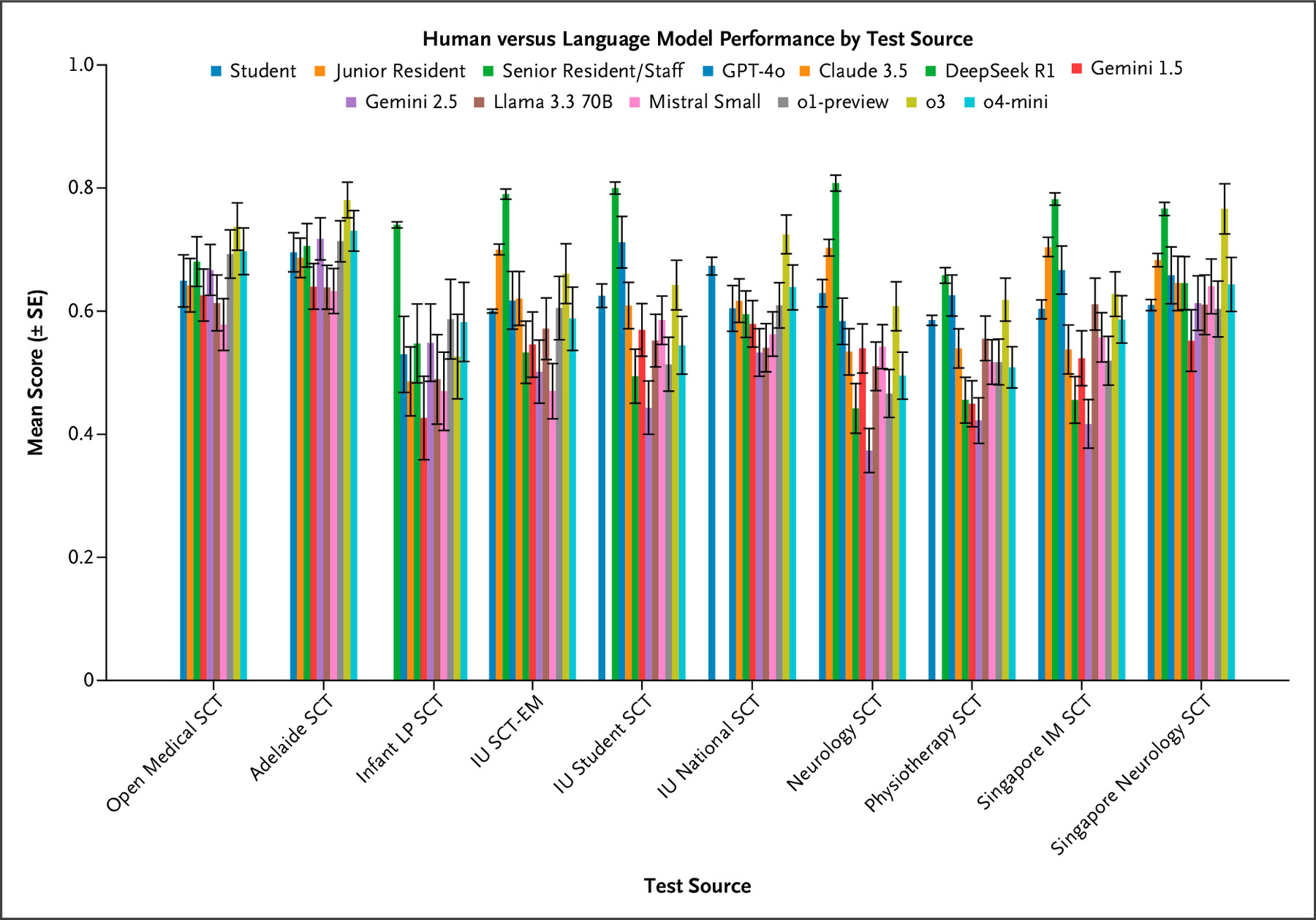
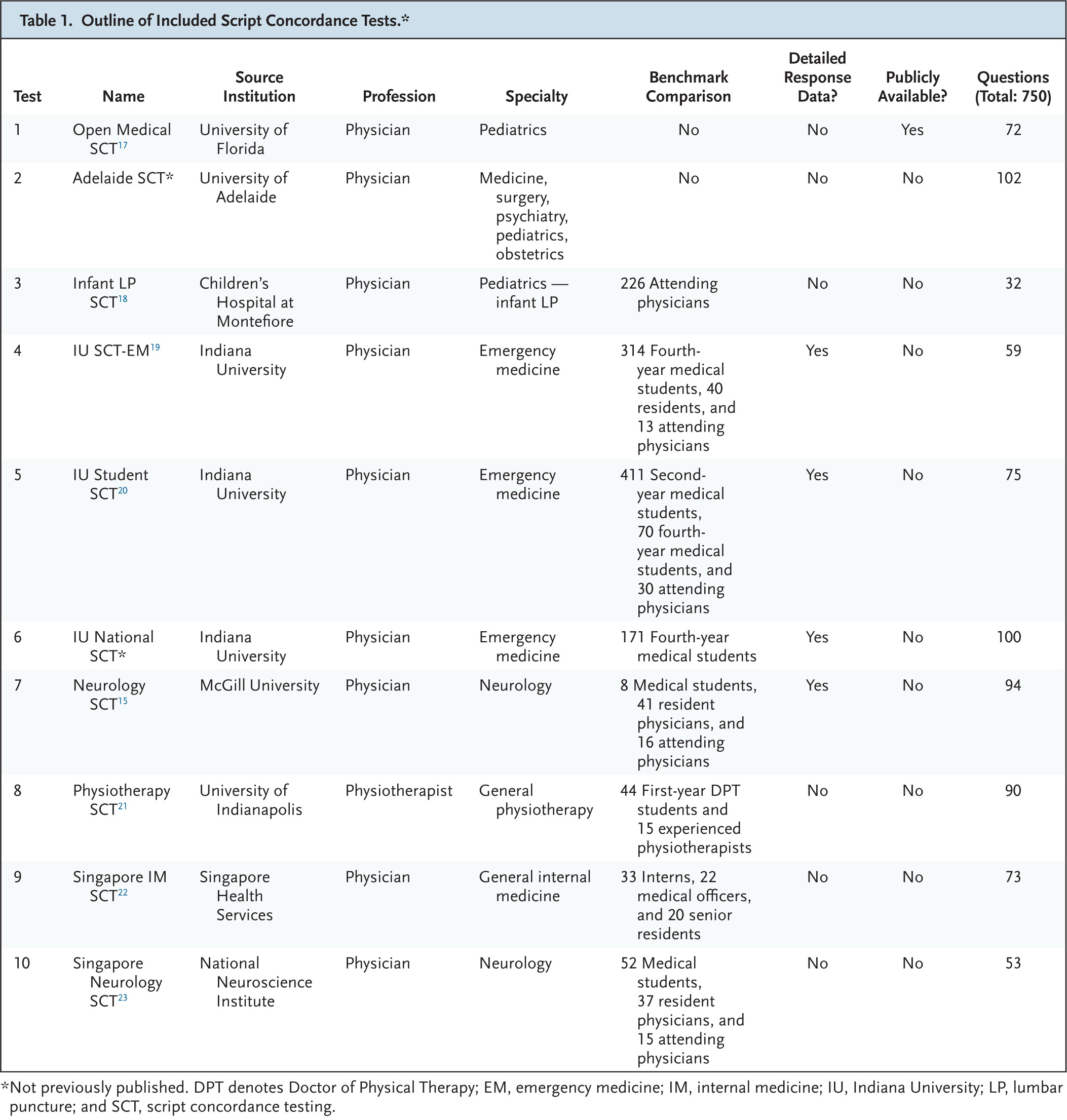
We built a public benchmark of 750 SCT questions drawn from 10 international, diverse datasets — 9 of which were newly released — spanning multiple specialties. Each item presents a clinical vignette and asks how added data change the likelihood of a diagnosis or management option, scored against expert-panel responses. Ten state-of-the-art LLMs were compared with 1070 medical students (1026 medical; 44 physiotherapy), 193 residents, and 300 attending physicians.
RESULTS
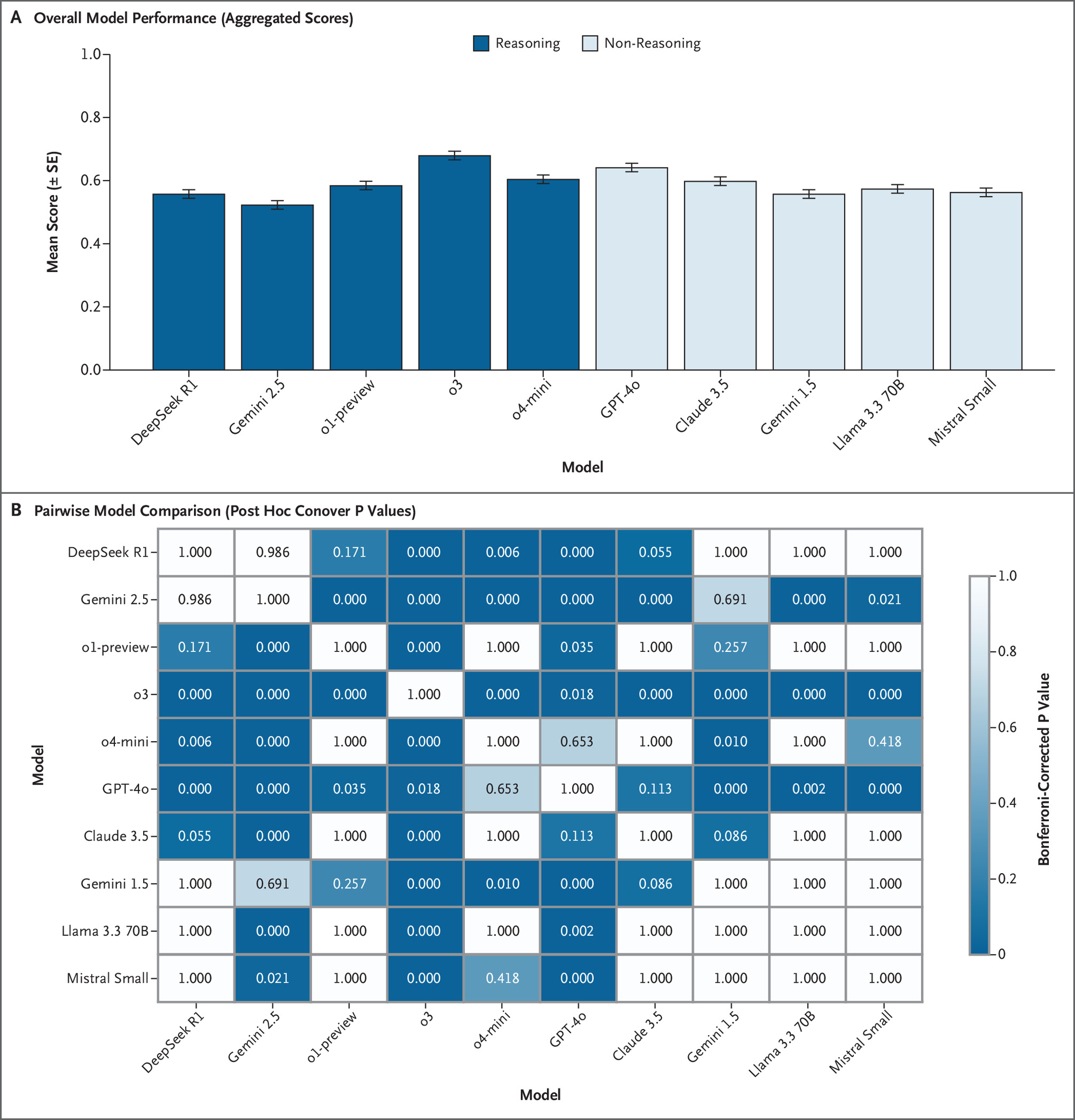
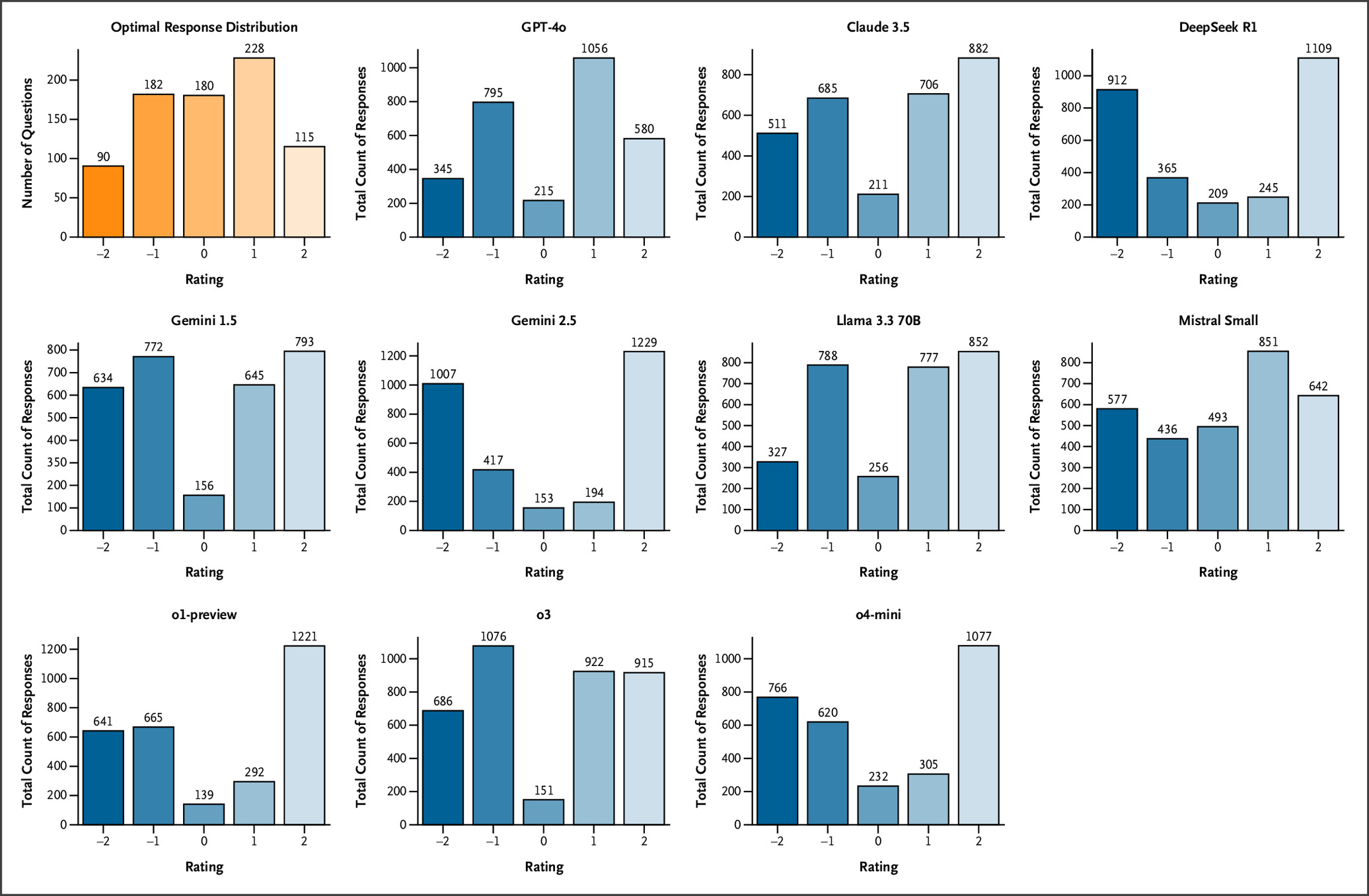
LLMs demonstrated markedly lower performance on SCT than their typical achievement on medical multiple-choice benchmarks. Across prompting conditions, OpenAI’s o3 achieved the highest performance (67.8%±1.2%), followed by GPT-4o (63.9%±1.3%). Other reasoning-optimized models, including OpenAI’s o1-preview (58.2%±1.3%) and DeepSeek R1 (55.5%±1.4%), performed significantly lower, with Google’s Gemini 2.5 Pro Preview (Gemini 2.5) (52.1%±1.4%) exhibiting the poorest results overall, while other non-reasoning models showed middling performance. Models matched or exceeded student performance on multiple examinations but did not reach the level of senior residents or attending physicians. Response-pattern analysis showed systematic overconfidence, with reasoning-tuned models overusing extreme ratings (+2/−2) and seldom choosing 0, implying that chain-of-thought optimizations may hinder flexible clinical reasoning under uncertainty.
CONCLUSIONS
SCT exposes persistent limitations in LLM clinical reasoning, especially in models optimized for explicit reasoning. Although SCT performance offers analogies to human probabilistic adjustment, it represents only one facet of evaluating artificial intelligence decision support. Our human-validated benchmark, now publicly available, provides a rigorous tool for advancing the assessment of medical artificial intelligence systems. (Funded by the Fulbright Program and others.)